初めに
NISQAを使ってreazon-research/reazonspeechのデータを分析します
環境
- L4 GPU
- ubuntu22.04
分析処理の方向性
reazonspeechのデータフォーマット
huggingfaceから取得したreazonspeechのデータセットを使いためには、以下の対応をする必要があります。
まず前提として リポジトリのReadMeよりデータフォーマットは以下のようになっています
Audio files are available in FLAC format, sampled at 16000 hz. Each audio file is accompanied with a transcription.
{ 'name': '000/0000000000000.flac', 'audio': { 'path': '/path/to/000/0000000000000.flac', 'array': array([ 0.01000000, ...], dtype=float32), 'sampling_rate': 16000 }, 'transcription': '今日のニュースをお伝えします。' }
NISQAの実行方法について
NISQAはReadMe及びコードを見るところ、以下の条件があります * wavファイルのみ対象 * CLIから処理をする方法が一般的(関数にwavファイルを渡すなどは想定していない?)
一つのファイルを処理をする場合、以下のように実行します
python run_predict.py --mode predict_file --pretrained_model weights/nisqa.tar --deg /path/to/wav/file.wav --output_dir /path/to/dir/with/results
またディレクトリ内のファイル全てに対しては以下のように実行します
python run_predict.py --mode predict_dir --pretrained_model weights/nisqa.tar --data_dir /path/to/folder/with/wavs --num_workers 0 --bs 10 --output_dir /path/to/dir/with/results
分析の方向性
上記の二つより以下の対応をする必要があります 1. flacファイルからwavファイルに変換 2. ディレクトリ内にwavファイルを入れて、CLI上からNISQAの処理をする
前処理
reazonspeechのデータをflacに変換
linux上で datasets から以下の処理でデータを取得した場合は、以下のような形でキャッシュされています。(少なくとも手元の環境では)
from datasets import load_dataset ds = load_dataset("reazon-research/reazonspeech", "all", trust_remote_code=True)
キャッシュのパスは 以下の通りです
~/.cache/huggingface/datasets/reazon-research___reazonspeech/tiny/0.0.0/e16d1ee2aae813b6ea960f564f4dc8481f58bfa6074be491eb4a6ddde66330bb
キャッシュは以下のようになっています
reazonspeech-train.arrow
そのため、arrowファイルからflacに一度変換をします
詳細は以下の記事を確認してください
flacファイルをwavファイルに変換
flacファイルができたので、以下で全てwavファイルに変換をします
詳細は以下をご確認ください
NISQAでwavファイルを分析
wavファイルに変換が終わったら、以下でNISQAを使って処理を実行します
python run_predict.py --mode predict_dir --pretrained_model weights/nisqa.tar --data_dir convert_wav/ --num_workers 0 --bs 2 --output_dir .
変換処理が終わったら、NISQA_results.csv というファイルが生成されます。内容は以下のようになっています(一部のみを記載しています)
| deg | mos_pred | noi_pred | dis_pred | col_pred | loud_pred | model |
|---|---|---|---|---|---|---|
| 1 | 2.3836768 | 1.8683524 | 3.9964635 | 3.6280687 | 3.5253642 | NISQAv2 |
| 2 | 1.5204918 | 1.5145079 | 3.7368195 | 2.7644107 | 2.5888093 | NISQAv2 |
| 3 | 3.1642735 | 2.5920422 | 3.9088361 | 3.5170329 | 3.714206 | NISQAv2 |
| 4 | 2.9011464 | 1.65048 | 4.631492 | 4.208716 | 4.005361 | NISQAv2 |
| 5 | 3.2035732 | 2.8596961 | 3.8604171 | 3.57778 | 3.71185 | NISQAv2 |
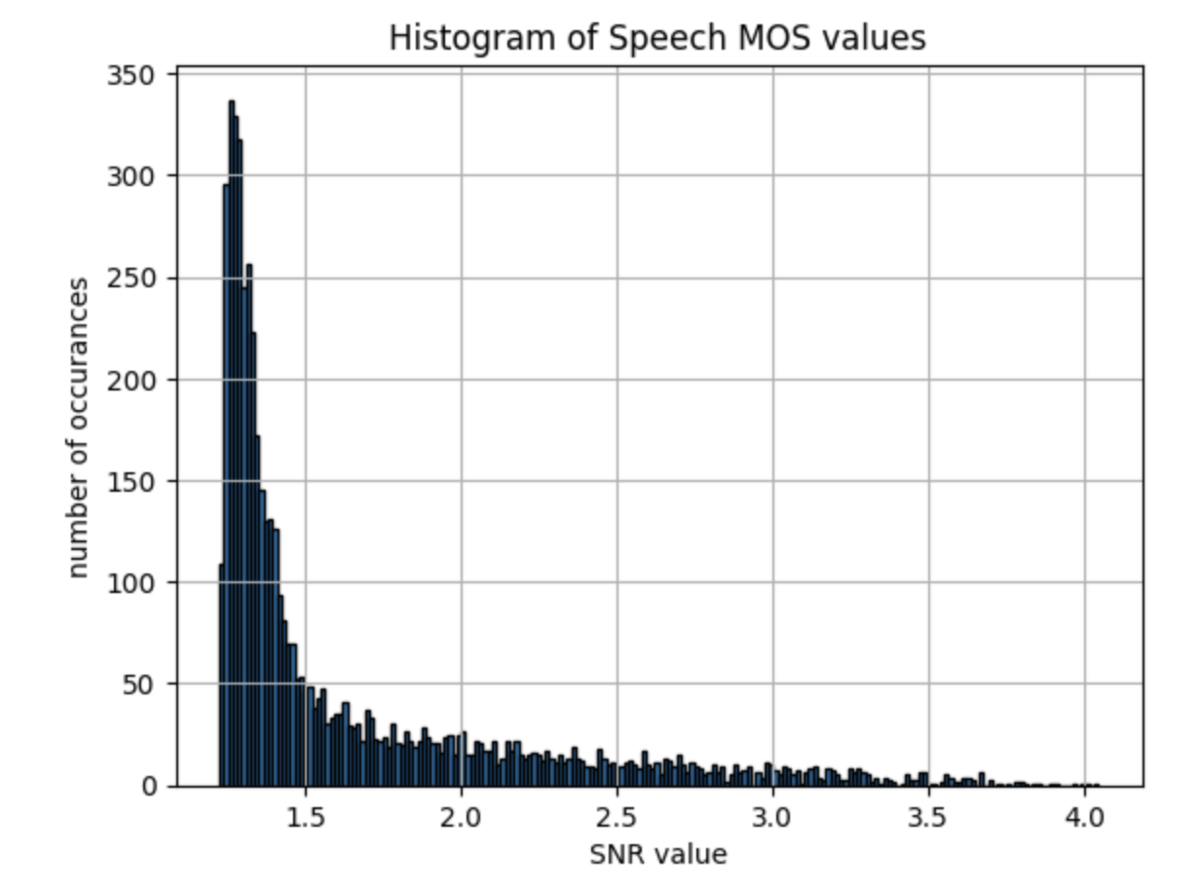
CSVから分析
以下のコードを使って、CSVからデータを取得してヒストグラムとして表示していきます
import pandas as pd import matplotlib.pyplot as plt # CSVファイルを読み込む data = pd.read_csv('NISQA_results.csv') bins = 80 # ヒストグラムのプロット plt.figure(figsize=(10, 6)) plt.subplot(2, 3, 1) plt.hist(data['mos_pred'], bins=bins, edgecolor='black') plt.xlabel('MOS Prediction') plt.ylabel('Frequency') plt.title('Histogram of MOS Prediction') plt.subplot(2, 3, 2) plt.hist(data['noi_pred'], bins=bins, edgecolor='black') plt.xlabel('Noise Prediction') plt.ylabel('Frequency') plt.title('Histogram of Noise Prediction') plt.subplot(2, 3, 3) plt.hist(data['dis_pred'], bins=bins, edgecolor='black') plt.xlabel('Distortion Prediction') plt.ylabel('Frequency') plt.title('Histogram of Distortion Prediction') plt.subplot(2, 3, 4) plt.hist(data['col_pred'], bins=bins, edgecolor='black') plt.xlabel('Coloration Prediction') plt.ylabel('Frequency') plt.title('Histogram of Coloration Prediction') plt.subplot(2, 3, 5) plt.hist(data['loud_pred'], bins=bins, edgecolor='black') plt.xlabel('Loudness Prediction') plt.ylabel('Frequency') plt.title('Histogram of Loudness Prediction') plt.tight_layout() plt.show()