初めに
前回は、WADR-SNRで分析をしました。今回は SpeechMOSを使って音声の品質を分析していきます
環境
- Google Colob(CPU)
準備
必要なライブラリを入れていきます
!pip install datasets librosa IPython numpy scipy soundfile matplotlib
データをダウンロードします
from datasets import load_dataset # データセットをロード ds = load_dataset("reazon-research/reazonspeech", "tiny")
SpeechMOSによるデータ分析
以下でSpeechMOSの値を計算して、jsonに保存していきます
import torch import librosa import json import numpy as np from datasets import load_dataset # speech-mosの予測器を初期化 predictor = torch.hub.load("tarepan/SpeechMOS:v1.2.0", "utmos22_strong", trust_repo=True) # データを前処理するための関数 def preprocess_audio(data): # データが整数型の場合、浮動小数点型に変換 if data.dtype == np.int16: data = data.astype(np.float32) / np.iinfo(np.int16).max elif data.dtype == np.int32: data = data.astype(np.float32) / np.iinfo(np.int32).max # ステレオをモノラルに変換(必要があれば) if len(data.shape) == 2: data = data.mean(axis=1) return data def process_audio_data(data): # 音声データを読み込む audio_data = data['audio']['array'] sr = data['audio']['sampling_rate'] # データを前処理 audio_data = preprocess_audio(audio_data) # speech-mosを使用して数値を取得 audio_data_tensor = torch.from_numpy(audio_data).unsqueeze(0).to(torch.float32) # float32に変換 score = predictor(audio_data_tensor.to(torch.float32), sr) # 入力データをfloat32に変換 # 結果を辞書に格納 result = { "ファイル名": data['name'], "MOS値": float(score), "トランスクリプション": data['transcription'] } # 不要な変数を削除してメモリを解放 del audio_data, audio_data_tensor return result def process_and_save_results(ds): for data in ds['train']: result = process_audio_data(data) yield result # 結果を保存するジェネレータ関数 def save_results_to_json(ds): with open('audio_analysis_results.json', 'w') as f: f.write('[\n') for i, result in enumerate(process_and_save_results(ds)): print("ファイル名:" + result["ファイル名"] + ", MOS値:" + str(result["MOS値"])) print("トランスクリプション: ", result["トランスクリプション"]) json.dump(result, f, ensure_ascii=False, indent=4) if i < len(ds['train']) - 1: f.write(',\n') f.write('\n]') print("JSONファイルが保存されました。") # 結果を保存 save_results_to_json(ds)
import json import matplotlib.pyplot as plt # JSONファイルからデータをロード file_path = 'audio_analysis_results.json' with open(file_path, 'r') as file: data = json.load(file) # SNR値のリストを抽出 snr_values = [item['MOS値'] for item in data] # ヒストグラムを描画 plt.hist(snr_values, bins=200, edgecolor='black') # binsは適宜調整してください plt.xlabel('SNR value') plt.ylabel('number of occurances') plt.title('Histogram of Speech MOS values') plt.grid(True) plt.show()
ヒストグラムで表示した際は以下のようになります
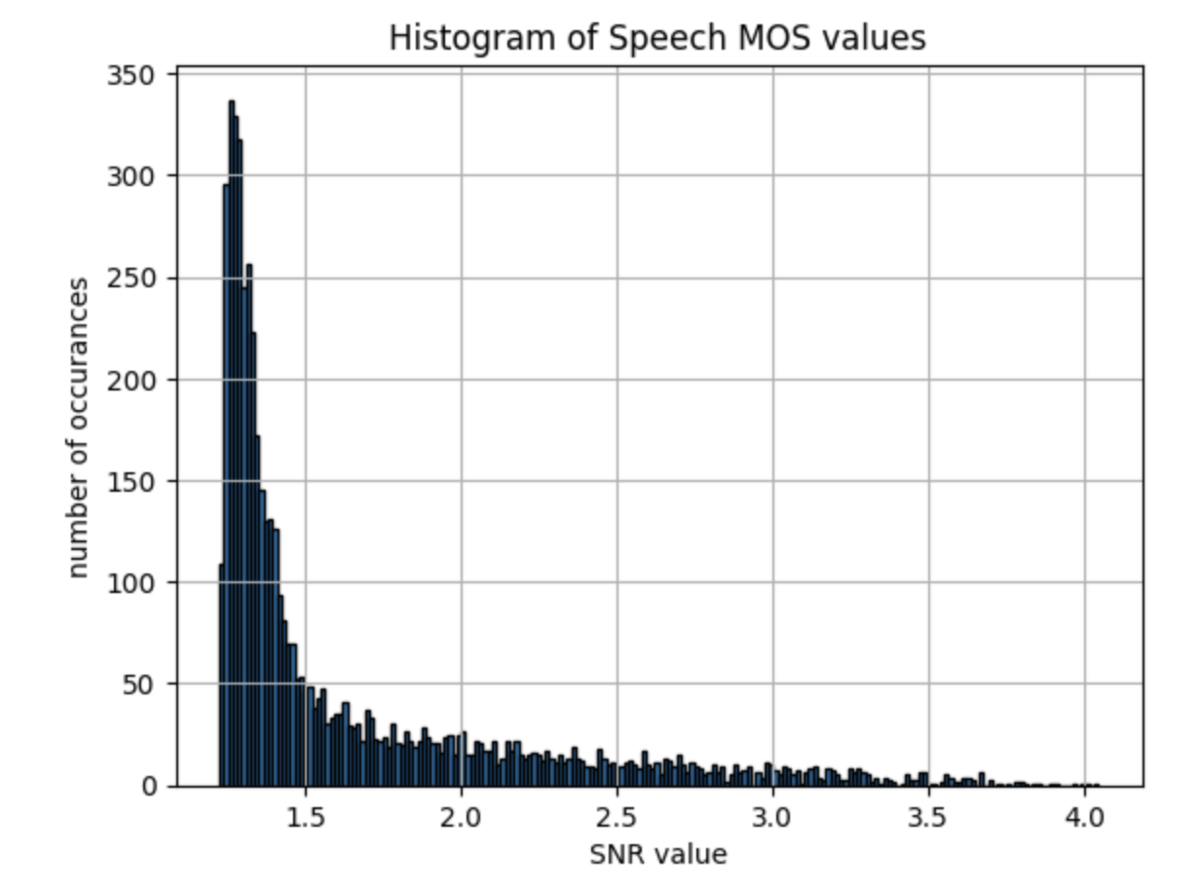
1区切りで見たさいに当てはまるデータ数は以下のように計算します
# SNR値が100以上のデータの数をカウント count_snr_above_1 = sum(1 for item in data if item['MOS値'] >= 1) count_snr_above_2 = sum(1 for item in data if item['MOS値'] >= 2) count_snr_above_3 = sum(1 for item in data if item['MOS値'] >= 3) print(f"SNR値が1以上のデータの数: {count_snr_above_1}") print(f"SNR値が2以上のデータの数: {count_snr_above_2}") print(f"SNR値が3以上のデータの数: {count_snr_above_3}")
実際の数値は以下のようになります
SNR値が1以上のデータの数: 5323 SNR値が2以上のデータの数: 1058 SNR値が3以上のデータの数: 224