初めに
拡散モデルのTTSで(一応)日本語対応されているライブラリの StableTTSを触っていきます
環境
- L4 GPU
- ubuntu22.04
ライブラリのインストール
まずは動かすために必要なライブラリをインストールします
内部で音声周りの処理をするために依存しているライブラリを入れます
sudo apt update sudo apt install ffmpeg
次に requirements.txt を入れるのですが、numpyが2.0.0が公開された影響でバグるので requirements.txt を変更して numpy<2にします
以下が変更した requirements.txtです
torch torchaudio matplotlib numpy<2 tensorboard pypinyin jieba eng_to_ipa unidecode inflect pyopenjtalk-prebuilt numba tqdm IPython gradio soundfile
モデルのアップロード
TTSの音声合成をするために、公式のモデルをダウンロードして配置をします。ただし日本語の事前学習モデルは公式から提供されていないため、今回は英語のモデルを使用します

上記のURLから vocoder.pt とcheckpoint-en_0.pt をダウンロードして、checkpoints/ 以下に配置します
WebUI画面の起動
以下にて、Web画面を起動できます
python webui.py
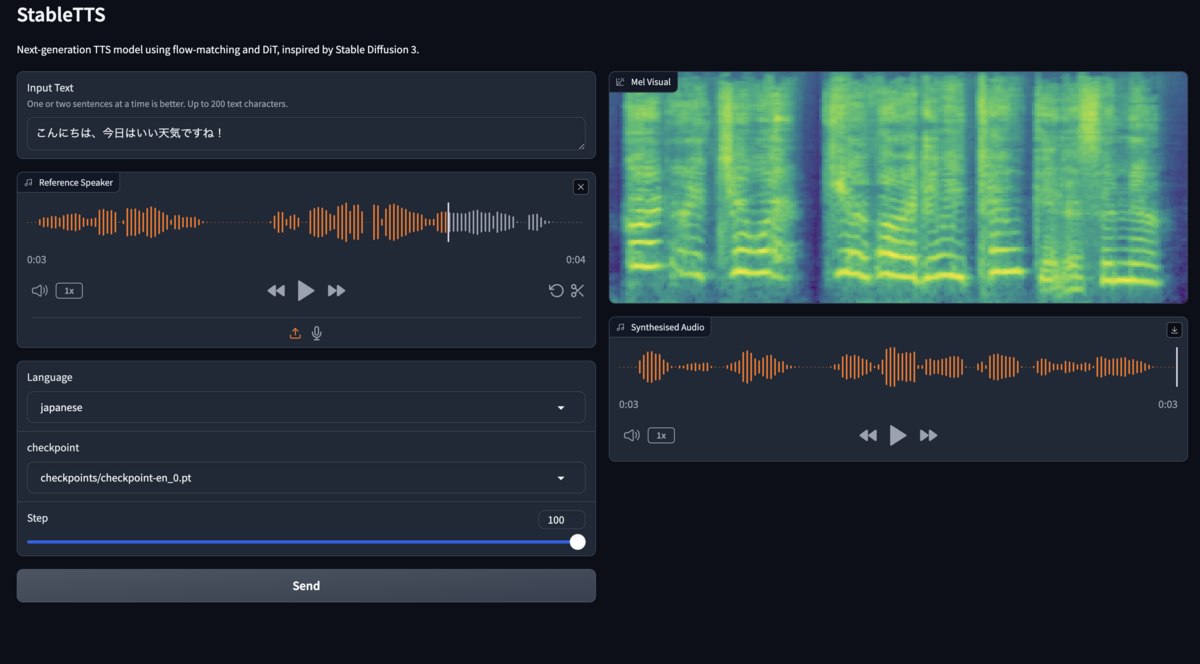
音声合成
以下を入力して、Sendを押すことで音声合成ができます。Step数を上げることでより精度が上がります(多分)
- Input text(合成するテキスト文)
- Reference Speaker(参考にする音声)
- Language(言語設定)
合成される音声は、英語の事前学習モデルを使っているからか精度は良くないです
推論時間の計測
音声の推論時間を以下のコード差分により計測を行いました
import time def inference(text: str, ref_audio: torch.Tensor, language: str, checkpoint_path: str, step: int=10) -> torch.Tensor: start_time = time.time() # 関数の開始時間を記録 global last_checkpoint_path if checkpoint_path != last_checkpoint_path: load_start = time.time() tts_model.load_state_dict(torch.load(checkpoint_path, map_location='cpu')) last_checkpoint_path = checkpoint_path load_end = time.time() print(f"Model loading time: {load_end - load_start:.2f} seconds") phonemizer = g2p_mapping.get(language) prep_start = time.time() # prepare input for tts model x = torch.tensor(intersperse(cleaned_text_to_sequence(phonemizer(text)), item=0), dtype=torch.long, device=device).unsqueeze(0) x_len = torch.tensor([x.size(-1)], dtype=torch.long, device=device) waveform, sr = torchaudio.load(ref_audio) if sr != sample_rate: waveform = torchaudio.functional.resample(waveform, sr, sample_rate) y = mel_extractor(waveform).to(device) prep_end = time.time() print(f"Input preparation time: {prep_end - prep_start:.2f} seconds") # inference inference_start = time.time() mel = tts_model.synthesise(x, x_len, step, y=y, temperature=1, length_scale=1)['decoder_outputs'] audio = vocoder(mel) inference_end = time.time() print(f"Inference time: {inference_end - inference_start:.2f} seconds") # process output for gradio post_start = time.time() audio_output = (sample_rate, (audio.cpu().squeeze(0).numpy() * 32767).astype(np.int16)) # (samplerate, int16 audio) for gr.Audio mel_output = plot_mel_spectrogram(mel.cpu().squeeze(0).numpy()) # get the plot of mel post_end = time.time() print(f"Post-processing time: {post_end - post_start:.2f} seconds") end_time = time.time() # 関数の終了時間を記録 total_time = end_time - start_time print(f"Total execution time: {total_time:.2f} seconds") return audio_output, mel_output
Input preparation time: 1.10 seconds Inference time: 1.88 seconds Post-processing time: 0.04 seconds Total execution time: 3.08 seconds Input preparation time: 0.08 seconds Inference time: 0.23 seconds Post-processing time: 0.03 seconds Total execution time: 0.34 seconds
備考
動いた時点の各ライブラリのverリストです
Package Version ------------------------- ----------- absl-py 2.1.0 aiofiles 23.2.1 altair 5.3.0 annotated-types 0.7.0 anyio 4.4.0 asttokens 2.4.1 attrs 23.2.0 certifi 2024.6.2 cffi 1.16.0 charset-normalizer 3.3.2 click 8.1.7 contourpy 1.2.1 cycler 0.12.1 Cython 3.0.10 decorator 5.1.1 dnspython 2.6.1 email_validator 2.2.0 eng-to-ipa 0.0.2 exceptiongroup 1.2.1 executing 2.0.1 fastapi 0.111.0 fastapi-cli 0.0.4 ffmpy 0.3.2 filelock 3.15.3 fonttools 4.53.0 fsspec 2024.6.0 gradio 4.36.1 gradio_client 1.0.1 grpcio 1.64.1 h11 0.14.0 httpcore 1.0.5 httptools 0.6.1 httpx 0.27.0 huggingface-hub 0.23.4 idna 3.7 importlib_resources 6.4.0 inflect 7.3.0 ipython 8.25.0 jedi 0.19.1 jieba 0.42.1 Jinja2 3.1.4 jsonschema 4.22.0 jsonschema-specifications 2023.12.1 kiwisolver 1.4.5 llvmlite 0.43.0 Markdown 3.6 markdown-it-py 3.0.0 MarkupSafe 2.1.5 matplotlib 3.9.0 matplotlib-inline 0.1.7 mdurl 0.1.2 more-itertools 10.3.0 mpmath 1.3.0 networkx 3.3 numba 0.60.0 numpy 1.26.4 nvidia-cublas-cu12 12.1.3.1 nvidia-cuda-cupti-cu12 12.1.105 nvidia-cuda-nvrtc-cu12 12.1.105 nvidia-cuda-runtime-cu12 12.1.105 nvidia-cudnn-cu12 8.9.2.26 nvidia-cufft-cu12 11.0.2.54 nvidia-curand-cu12 10.3.2.106 nvidia-cusolver-cu12 11.4.5.107 nvidia-cusparse-cu12 12.1.0.106 nvidia-nccl-cu12 2.20.5 nvidia-nvjitlink-cu12 12.5.40 nvidia-nvtx-cu12 12.1.105 orjson 3.10.5 packaging 24.1 pandas 2.2.2 parso 0.8.4 pexpect 4.9.0 pillow 10.3.0 pip 22.0.2 prompt_toolkit 3.0.47 protobuf 4.25.3 ptyprocess 0.7.0 pure-eval 0.2.2 pycparser 2.22 pydantic 2.7.4 pydantic_core 2.18.4 pydub 0.25.1 Pygments 2.18.0 pyopenjtalk-prebuilt 0.3.0 pyparsing 3.1.2 pypinyin 0.51.0 python-dateutil 2.9.0.post0 python-dotenv 1.0.1 python-multipart 0.0.9 pytz 2024.1 PyYAML 6.0.1 referencing 0.35.1 requests 2.32.3 rich 13.7.1 rpds-py 0.18.1 ruff 0.4.10 semantic-version 2.10.0 setuptools 59.6.0 shellingham 1.5.4 six 1.16.0 sniffio 1.3.1 soundfile 0.12.1 stack-data 0.6.3 starlette 0.37.2 sympy 1.12.1 tensorboard 2.17.0 tensorboard-data-server 0.7.2 tomlkit 0.12.0 toolz 0.12.1 torch 2.3.1 torchaudio 2.3.1 tqdm 4.66.4 traitlets 5.14.3 triton 2.3.1 typeguard 4.3.0 typer 0.12.3 typing_extensions 4.12.2 tzdata 2024.1 ujson 5.10.0 Unidecode 1.3.8 urllib3 2.2.2 uvicorn 0.30.1 uvloop 0.19.0 watchfiles 0.22.0 wcwidth 0.2.13 websockets 11.0.3 Werkzeug 3.0.3