初めに
UnityがUnitySentisを使ってTTSを実装できるようなサンプル?モデルを公開しているので、動かしていきます
Demo
デモでは、文字を入力した後にspaceを押して音声を生成・再生しています
リポジトリは以下で公開しています
開発環境
- Unity 2023.3.0b2
- unity.sentis : 1.4.0-pre.2
- MacOS 14.3.1
ライブラリのインストール
まずは、Unityを起動します。その後にUnity Sentisをインストールします
以下の画像ように Package Manager → Install package by name で以下を設定します
name : com.unity.sentis version: 1.4.0-pre.2

モデルの設定
次にTTSを使用するためのモデルの設定を行います
Unityでは、TTSのモデル(pthやsafetensors)は扱いづらいので、ONNXにしたものを使用します
今回は、以下で公式が公開していているunity/sentis-jets-text-to-speechを使用します
以下のコマンドでリポジトリをcloneします
git lfs install git clone https://huggingface.co/unity/sentis-jets-text-to-speech
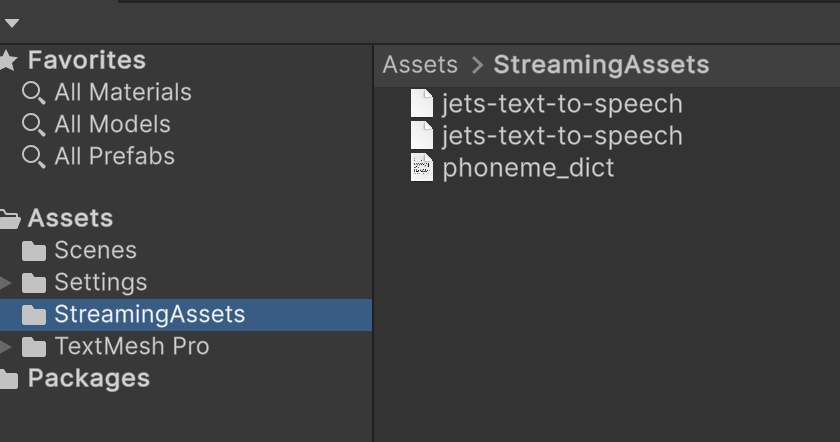
こららのフォルダを以下の画像のように配置します
この時に sentis ファイル phoneme_dict.txt ファイルをAssets/StreamingAssets のディレクトリ に入れないと動きません
Assets/StreamingAssets
スクリプトの設定
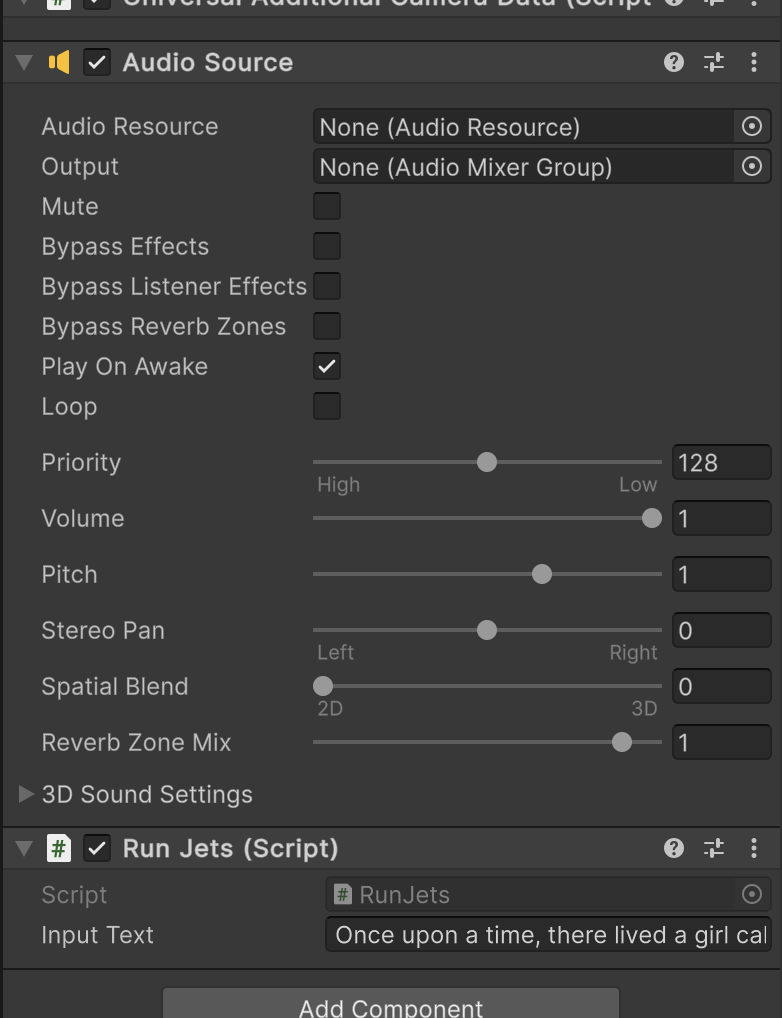
次に UnityでONNX経由してTTSを行うためにスクリプトを設定します。
画像のように公式が用意している RunJets を 任意のところにアタッチします。この時に AudioSource を同じオブジェクトにアタッチします
TTSの実行と再生
デモ動画はInput Fieldから自由に入力できるようにしていますが、記事の場合はInspecotorから文字を入れることで任意の文字から音声を生成できます
任意の文字を入れて実行すると音声が生成されて、再生されます