初めに
前回の記事でljspeechデータセットを使った英語のモデルを作成しました。今回は日本語モデルを作成していきます
開発環境
前処理や調査
学習環境
データセットの準備
jvsデータセットをljspeechデータセットフォーマットに変換
まずは piperで学習する際にljspeechフォーマットになっているのが好ましいため、jvsデータセットをljspeechデータセットのフォーマットに変換をします
まずはjvsデータセットをダウンロードして以下のような構造にします
C:\Users\yuta\Downloads\jvs_ver1\ ├── .venv/ ├── jvs_ver1/ │ ├── jvs001/ │ ├── jvs002/ │ ├── jvs003/ │ ├── jvs004/ │ ├── ..... (~100まで) │ ├── duration_info.txt │ ├── gender_f0range.txt │ ├── paper.pdf │ ├── README.txt │ ├── speaker_similarity_female.csv │ └── speaker_similarity_male.csv ├── result/ ├── jvs_to_ljspeech_multi.py ├── jvs_to_ljspeech.py └── process_japanese_metadata_plus.py
jvsのデータ構造からljspeechに変換するために、以下のスクリプトを実行します。piperの学習において複数話者の場合は、metadataの構造を以下のようにする必要があります
id|話者名|文字お越し
具体的には以下のようなデータになります
jvs001_falset10_VOICEACTRESS100_001|jvs001|また、東寺のように、五大明王と呼ばれる、主要な明王の中央に配されることも多い。 jvs001_falset10_VOICEACTRESS100_002|jvs001|ニューイングランド風は、牛乳をベースとした、白いクリームスープであり、ボストンクラムチャウダーとも呼ばれる。
以下が実際の変換用のコードです
import os import shutil import csv def convert_jvs_to_multispeaker_format(jvs_root_dir, output_dir_name="result", metadata_filename="metadata_multispeaker.csv"): """ JVSデータセットを複数話者TTS学習用のフォーマットに変換する。 metadataファイルは3列構成 (ID拡張子なし|話者ID|テキスト)。 出力WAVファイル名は speaker_dir_name と sub_dir_name を含めることで重複を回避。 Args: jvs_root_dir (str): JVSデータセットのルートディレクトリパス。 output_dir_name (str): 出力する親フォルダの名前。 metadata_filename (str): 出力するメタデータファイルの名前。 """ current_path = os.getcwd() output_base_dir = os.path.join(current_path, output_dir_name) output_wavs_dir = os.path.join(output_base_dir, "wavs") output_metadata_file = os.path.join(output_base_dir, metadata_filename) if os.path.exists(output_base_dir): print(f"警告: 出力ディレクトリ '{output_base_dir}' は既に存在します。中のファイルが上書きされる可能性があります。") os.makedirs(output_wavs_dir, exist_ok=True) metadata_list = [] # メタデータを格納するリスト processed_files_count = 0 missing_files_os_path_exists_count = 0 missing_files_is_file_count = 0 missing_files_open_rb_count = 0 copy_errors_count = 0 print(f"JVSデータセットの処理を開始します: {jvs_root_dir}") print(f"出力先ディレクトリ: {output_base_dir}") for speaker_dir_name in sorted(os.listdir(jvs_root_dir)): # 例: jvs001, jvs002 speaker_path = os.path.join(jvs_root_dir, speaker_dir_name) if not os.path.isdir(speaker_path): continue print(f" 話者ディレクトリを処理中: {speaker_dir_name}") for sub_dir_name in sorted(os.listdir(speaker_path)): # 例: falset10, nonpara30 sub_dir_path = os.path.join(speaker_path, sub_dir_name) if not os.path.isdir(sub_dir_path): continue transcript_file_path = os.path.join(sub_dir_path, 'transcripts_utf8.txt') actual_wav_files_location = None potential_wav_subfolder_names = ['wav24kHz16bit', 'wav48kHz16bit', 'wav', 'voice'] for folder_name in potential_wav_subfolder_names: current_check_dir = os.path.join(sub_dir_path, folder_name) if os.path.isdir(current_check_dir): if any(f.endswith('.wav') for f in os.listdir(current_check_dir)): actual_wav_files_location = current_check_dir break if not actual_wav_files_location: if os.path.isdir(sub_dir_path) and any(f.endswith('.wav') for f in os.listdir(sub_dir_path)): actual_wav_files_location = sub_dir_path if not actual_wav_files_location: if os.path.exists(transcript_file_path): print(f" 警告: '{sub_dir_path}' 内で音声ファイルの場所を特定できませんでした (トランスクリプト '{transcript_file_path}' は存在します)。このサブディレクトリをスキップします。") continue if os.path.exists(transcript_file_path): print(f" 処理中のサブディレクトリ: '{sub_dir_path}' (音声ファイルの場所: '{actual_wav_files_location}')") print(f" トランスクリプトファイル: '{transcript_file_path}'") with open(transcript_file_path, 'r', encoding='utf-8') as f: for line_number, line in enumerate(f, 1): line = line.strip() if not line: continue try: original_audio_basename, text = line.split(':', 1) # original_audio_basename は拡張子なし except ValueError: print(f" 警告 (行 {line_number}): 不正な行フォーマットです: \"{line}\"。スキップします。") continue original_wav_filename_with_ext = original_audio_basename + ".wav" source_wav_path = os.path.join(actual_wav_files_location, original_wav_filename_with_ext) if not os.path.exists(source_wav_path): missing_files_os_path_exists_count += 1 continue if not os.path.isfile(source_wav_path): print(f" 警告 (行 {line_number}): パスは存在するがファイルではありません (os.path.isfile): '{source_wav_path}'。スキップします。") missing_files_is_file_count += 1 continue try: with open(source_wav_path, 'rb') as f_test: pass except Exception as e_test: print(f" 警告 (行 {line_number}): ファイルは存在するが、開けません (open 'rb' test): '{source_wav_path}'。エラー: {e_test}。スキップします。") missing_files_open_rb_count += 1 continue # --- メタデータ用IDと実際のコピーファイル名の生成 --- # メタデータ用ID (拡張子なし) file_id_no_ext = f"{speaker_dir_name}_{sub_dir_name}_{original_audio_basename}" # 実際にコピーされるファイル名 (拡張子あり) copied_wav_filename_with_ext = f"{speaker_dir_name}_{sub_dir_name}_{original_wav_filename_with_ext}" destination_wav_path = os.path.join(output_wavs_dir, copied_wav_filename_with_ext) try: shutil.copy2(source_wav_path, destination_wav_path) processed_files_count +=1 except FileNotFoundError: print(f" 重大エラー (行 {line_number}, shutil.copy2 FileNotFoundError): '{source_wav_path}' がコピー時に見つかりませんでした。") print(f" 再確認: os.path.exists={os.path.exists(source_wav_path)}, os.path.isfile={os.path.isfile(source_wav_path)}") copy_errors_count += 1 continue except Exception as e: print(f" エラー (行 {line_number}): 音声ファイルのコピーに失敗しました: '{source_wav_path}' -> '{destination_wav_path}'。エラー: {e}") copy_errors_count += 1 continue # 複数話者用メタデータとして (ID拡張子なし, 話者ID, テキスト) の3列を追加 speaker_id = speaker_dir_name # 話者IDはjvsXXXなど metadata_list.append([file_id_no_ext, speaker_id, text]) print(f"\n--- 処理結果サマリー ({metadata_filename}) ---") if metadata_list: with open(output_metadata_file, 'w', encoding='utf-8', newline='') as f_out: writer = csv.writer(f_out, delimiter='|', quoting=csv.QUOTE_NONE, escapechar='\\') for row in metadata_list: writer.writerow(row) print(f" メタデータは '{output_metadata_file}' に複数話者フォーマット (3列) で保存されました。") print(f" 処理され、コピーされた音声ファイルの総数: {processed_files_count} 個") if processed_files_count > 0 : print(f" コピーされた音声ファイルは '{output_wavs_dir}' にあります。") elif processed_files_count == 0 : print(f" 処理できる音声ファイルが見つからなかったため、メタデータファイルは作成されませんでした。") if missing_files_os_path_exists_count > 0: print(f" トランスクリプト記載があったが、存在しなかったファイル数 (os.path.exists): {missing_files_os_path_exists_count} 個") if missing_files_is_file_count > 0: print(f" パスは存在したがファイルではなかった数 (os.path.isfile): {missing_files_is_file_count} 個") if missing_files_open_rb_count > 0: print(f" ファイルは存在したが開けなかった数 (open 'rb' test): {missing_files_open_rb_count} 個") if copy_errors_count > 0: print(f" ファイルコピー時にエラーが発生した数: {copy_errors_count} 個") if not metadata_list and processed_files_count == 0 and \ missing_files_os_path_exists_count == 0 and missing_files_is_file_count == 0 and \ missing_files_open_rb_count == 0 and copy_errors_count == 0 : print(f" 処理対象のデータが全く見つかりませんでした。JVSのパスや構造を確認してください。") # (ここに前回の convert_jvs_to_piper_format 関数をそのまま残すことも可能です) # def convert_jvs_to_piper_format(jvs_root_dir, output_dir_name="result"): # ... (前回のコード) ... if __name__ == '__main__': jvs_input_path = r"C:\Users\yuta\Downloads\jvs_ver1\jvs_ver1" output_folder_name = "result" # 親フォルダ result print(f"スクリプトの実行パス: {os.getcwd()}") print(f"JVSデータセットの入力パス: {jvs_input_path}") print(f"出力フォルダ名: {output_folder_name}") if not os.path.isdir(jvs_input_path): print(f"エラー: 指定されたJVSデータセットのパスが見つかりません: {jvs_input_path}") else: # --- Piper用メタデータ生成を呼び出す場合 (ファイル名: metadata.csv) --- # convert_jvs_to_piper_format(jvs_input_path, output_folder_name) # --- 今回ご要望の複数話者用メタデータ生成を呼び出す場合 (ファイル名: metadata_multispeaker.csv) --- convert_jvs_to_multispeaker_format(jvs_input_path, output_folder_name, metadata_filename="metadata_multispeaker.csv") # --- もし両方生成したい場合は、両方の関数を呼び出すか、 # --- WAVコピー処理を共通化してメタデータ生成部分を分けるようにスクリプトをリファクタリングします。 # --- ここでは、新しい複数話者用フォーマットのみを生成する例としています。
これを実行することで、resultフォルダ内にwavsフォルダとmetadata.csvが生成されます
学習コード及び推論コードの日本語の音素の対応
piperのオリジナルリポジトリには、日本語の音素対応がしないため 学習をすると以下のwaringが出ます。このまま学習をしても日本語が正常に発話されません。
推論時に以下のようなwaringが出てきます
WARNING:piper.voice:Missing phoneme from id map: ̞ WARNING:piper.voice:Missing phoneme from id map: ̞ WARNING:piper.voice:Missing phoneme from id map: ̈ WARNING:piper.voice:Missing phoneme from id map: ̞ WARNING:piper.voice:Missing phoneme from id map: ̞ WARNING:piper.voice:Missing phoneme from id map: ̞ WARNING:piper.voice:Missing phoneme from id map: ̞ WARNING:piper.voice:Missing phoneme from id map: ᵝ WARNING:piper.voice:Missing phoneme from id map: ̞ WARNING:piper.voice:Missing phoneme from id map: ̞ WARNING:piper.voice:Missing phoneme from id map: ̈ WARNING:piper.voice:Missing phoneme from id map: ̞ WARNING:piper.voice:Missing phoneme from id map: ̞ WARNING:piper.voice:Missing phoneme from id map: ̞ WARNING:piper.voice:Missing phoneme from id map: ̞ WARNING:piper.voice:Missing phoneme from id map: ̞ WARNING:piper.voice:Missing phoneme from id map: ̞ WARNING:piper.voice:Missing phoneme from id map: ̞ WARNING:piper.voice:Missing phoneme from id map: ̞ WARNING:piper.voice:Missing phoneme from id map: ̞ WARNING:piper.voice:Missing phoneme from id map: ̞ WARNING:piper.voice:Missing phoneme from id map: ᵝ WARNING:piper.voice:Missing phoneme from id map: ̞ WARNING:piper.voice:Missing phoneme from id map: ̞ WARNING:piper.voice:Missing phoneme from id map: ᵝ WARNING:piper.voice:Missing phoneme from id map: ̞ WARNING:piper.voice:Missing phoneme from id map: ̞ WARNING:piper.voice:Missing phoneme from id map: ̈ WARNING:piper.voice:Missing phoneme from id map: ̞ WARNING:piper.voice:Missing phoneme from id map: ̞ WARNING:piper.voice:Missing phoneme from id map: ̞ WARNING:piper.voice:Missing phoneme from id map: ̞ WARNING:piper.voice:Missing phoneme from id map: ᵝ WARNING:piper.voice:Missing phoneme from id map: ̞ WARNING:piper.voice:Missing phoneme from id map: ̞ WARNING:piper.voice:Missing phoneme from id map: ̞ WARNING:piper.voice:Missing phoneme from id map: ̞ WARNING:piper.voice:Missing phoneme from id map: ᵝ
そのため、以下のような対応を入れました
pyopenjtalk を利用する専用 phonemizer phonemize_japanese を実装
- アクセント句境界 #・上昇 [・下降 ] などのプロソディ記号を付与
- 無声化母音 A I U E O → a i u e o に変換
- sil → 文頭 ^ / 文末 $ or ?、pau → _
日本語用 ID マップ jp_id_map.py を追加
- 特殊トークン(^ $ ? # [ ] )+ 50 余りの音素を列挙
--language ja 時は PhonemeType.OPENJTALK を強制し ID マップを注入
- 生成した config.json に phoneme_type=openjtalk, phoneme_id_map を保存
細かい対応は以下の差分を参考にしてください
学習
データセットが終わったら、以下の記事と同じように配置を行い学習を行います
途中から学習を再開する場合は、学習コマンドに --resume_from_checkpoint "${CHECKPOINT_PATH}" を付けて実行します
epoch650学習を行い以下がログになります
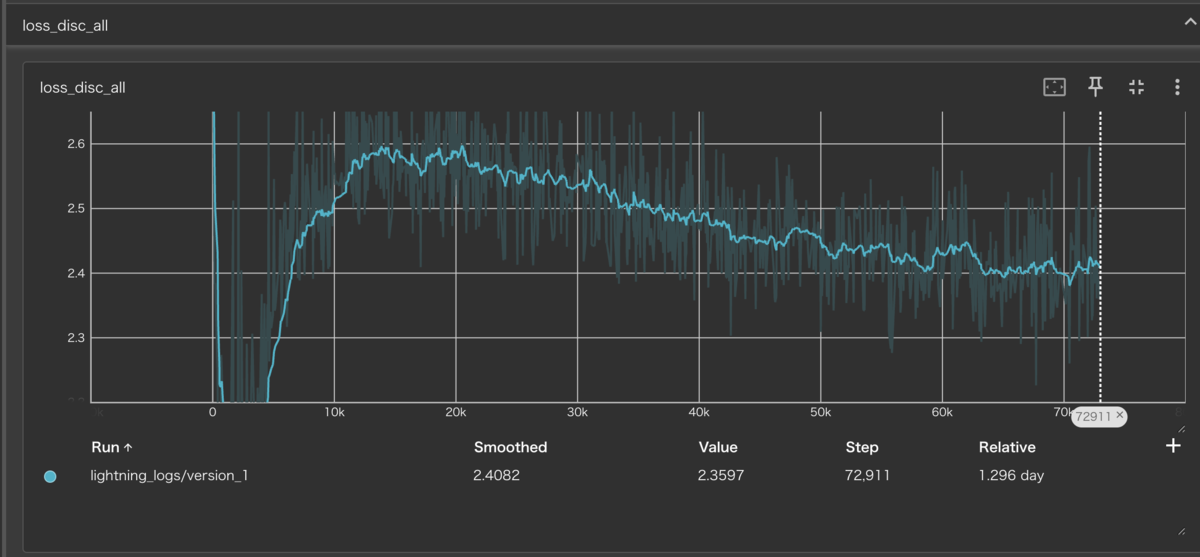
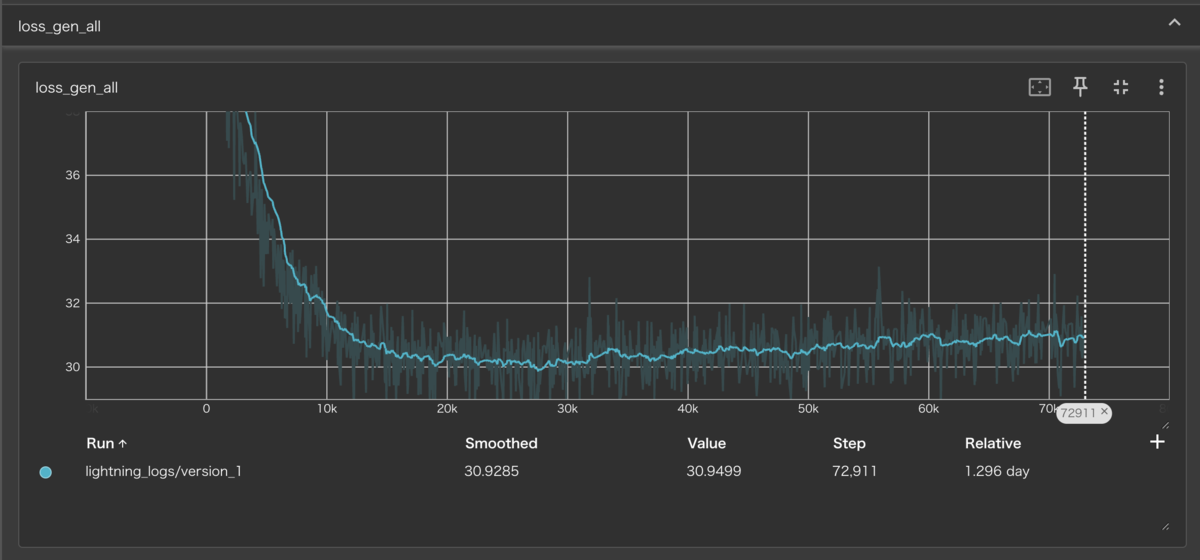
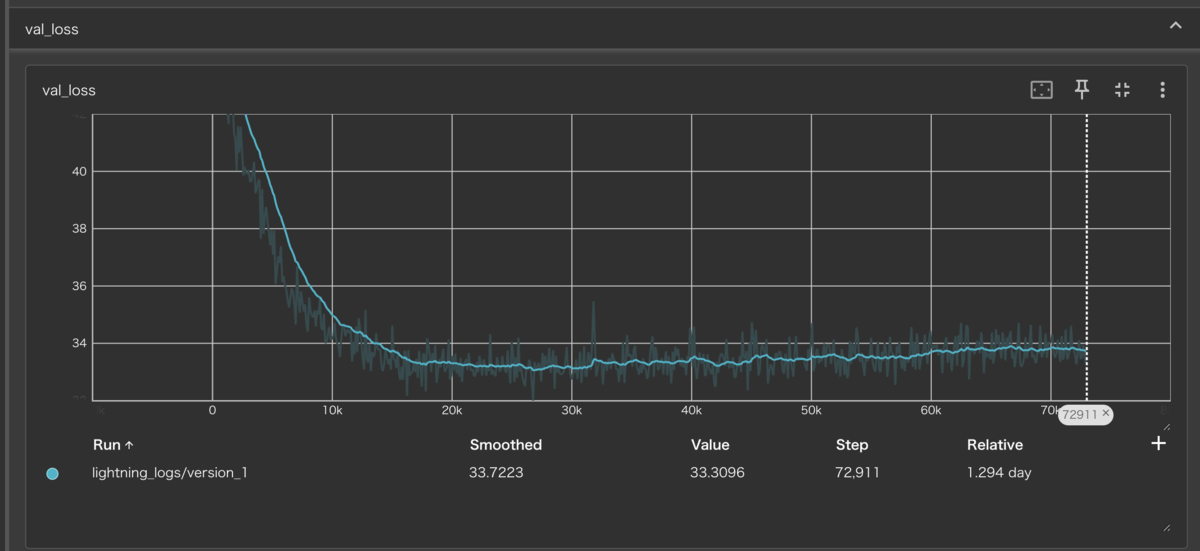
推論
学習した後に推論をするためにonnxに変換をします
python3 -m piper_train.export_onnx \ /data/piper_jvs_preprocessed_espeak_ms/lightning_logs/version_1/checkpoints/epoch=650-step=145824.ckpt \ /data/piper_MODELS_EXPORTED/jvs_piper_multi_epoch650.onnx
config.jsonも必要なため、コピーしてきます
cp /data/piper_jvs_preprocessed_espeak_ms/config.json \ /data/piper_MODELS_EXPORTED/jvs_piper_multi_epoch650.onnx.json
以下のコマンドでonnxに変換したモデルから日本語の推論を行います
echo "これは650エポック学習した、私の新しい日本語音声モデルです。聞いてみましょう。" | piper -m /data/piper_MODELS_EXPORTED/jvs_piper_multi_epoch650.onnx --output_file jvs_epoch650_test.wav --speaker 0
実際の音声は以下になります