初めに
いまさらですが、GPT-SoVITSのローカル推論を試していきます。今回はサーバー化したいため、fastAPIのサーバーを立てます
以下でuv 環境で記事の通りに以下の対応を行ったリポジトリを公開しています
- シンプルなクライアントコードを作成
- サーバーコードの修正
- uv環境の構築
開発環境
- Windows 11
- uv 0.4.16
- python 3.9.20
- GPT-SoVITS リンク先のハッシュ時点
準備
環境作成とライブラリのインストール
WindowsのPowerShellの場合は、以下でUTF-8 エンコーディングが上手くできるように設定をします
$env:PYTHONIOENCODING = "utf-8"
次にuvの環境を作成します
uv init python=3.9 uv
必要なライブラリをインストールします
uv add -r requirements.txt
uv add ffmpeg-python
uv add pyopenjtalk
この際にインストールされるtorchがcpuになっているので、そのまま動かす場合は GPT-SoVITS\GPT_SoVITS\configs\tts_infer.yaml の customのdeviceを以下のように cpu に変更します。またcpuでの実行の場合は、is_half をfalseにします
custom: bert_base_path: GPT_SoVITS/pretrained_models/chinese-roberta-wwm-ext-large cnhuhbert_base_path: GPT_SoVITS/pretrained_models/chinese-hubert-base device: cpu is_half: false t2s_weights_path: GPT_SoVITS/pretrained_models/gsv-v2final-pretrained/s1bert25hz-5kh-longer-epoch=12-step=369668.ckpt version: v2 vits_weights_path: GPT_SoVITS/pretrained_models/gsv-v2final-pretrained/s2G2333k.pth
GPU(CUDA)で処理をしたい場合は、以下でcuda版をインストールします
uv pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121 --force-reinstall
またこの際に tts_infer.yaml の customの設定をいかに変更します
device: cuda is_half: true
各モデルの配置
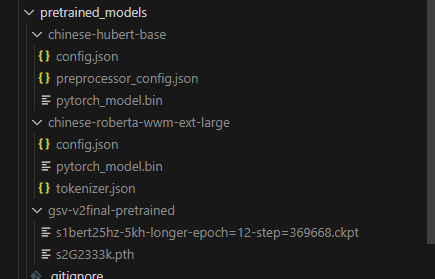
公式のモデルをcloneもしくはダウンロードしてきて、以下の画像のようにモデルを配置します
GPT_SoVITS/
├── pretrained_models/
├── chinese-hubert-base/
│ ├── config.json
│ ├── preprocessor_config.json
│ └── pytorch_model.bin
├── chinese-roberta-wwm-ext-large/
│ ├── config.json
│ ├── tokenizer.json
│ └── pytorch_model.bin
├── gsv-v2final-pretrained/
│ ├── s1bert25hz-5kh-longer-epoch=12-step=369668.ckpt
│ └── s2G2333k.pth
└── .gitignore
サーバーコードの修正
api_v2.py に以下を追加します
import ffmpeg
ローカルサーバーの起動
以下のコマンドでローカルサーバーを立てることができます
uv run api_v2.py -a 127.0.0.1 -p 9880 -c GPT_SoVITS/configs/tts_infer.yaml
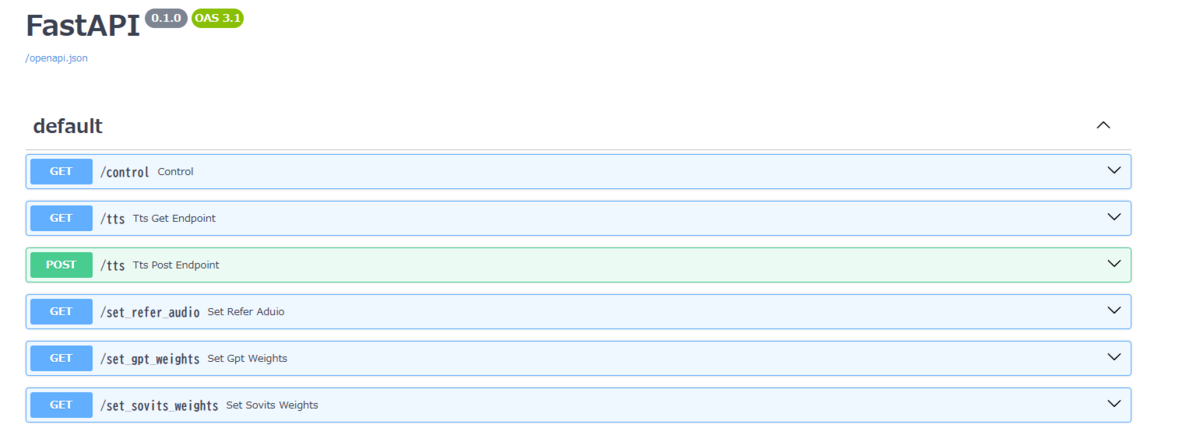
http://127.0.0.1:9880/docs にアクセスすると Swagger UIが表示されます
クライアントからサーバーを実行
今回はシンプルなクライアントコードを書いて実行をします
import requests def tts_get(): # GETリクエストのパラメータを設定 params = { 'text': 'こんにちは', 'text_lang': 'ja', 'ref_audio_path': 'ref_audio.wav', 'prompt_text': 'また、東寺のように、五大明王と呼ばれる、主要な明王の中央に配されることも多い。', 'prompt_lang': 'ja', 'media_type': 'wav', 'streaming_mode': 'false' } # GETリクエストを送信 response = requests.get('http://127.0.0.1:9880/tts', params=params) # レスポンスの処理 if response.status_code == 200: # 音声データをファイルに保存 with open('output_get.wav', 'wb') as f: f.write(response.content) print('音声ファイルをoutput_get.wavに保存しました。') else: print(f"エラー {response.status_code}: {response.text}") if __name__ == '__main__': tts_get()
実行することで以下の結果および音声ファイルが生成されます
uv run .\client.py 音声ファイルをoutput_get.wavに保存しました。
エラー対応
pyopenjtalkのインストールがうまくいかない場合
以下のライブラリを代用することでインストールが上手くいくことがあります。
以下でインストールすることができます
pip install pyopenjtalk-plus
torch関連が上手くいかない
個別に以下でインストールを行ってからほかのライブラリをインストールします。
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
特定のversionをインストールする場合は、以下のようにします
pip install torch==2.5.0 torchvision==0.20.0 torchaudio==2.5.0 --index-url https://download.pytorch.org/whl/cu121
CMakeがないと言われた場合
以下からダウンロードしてインストールを行います